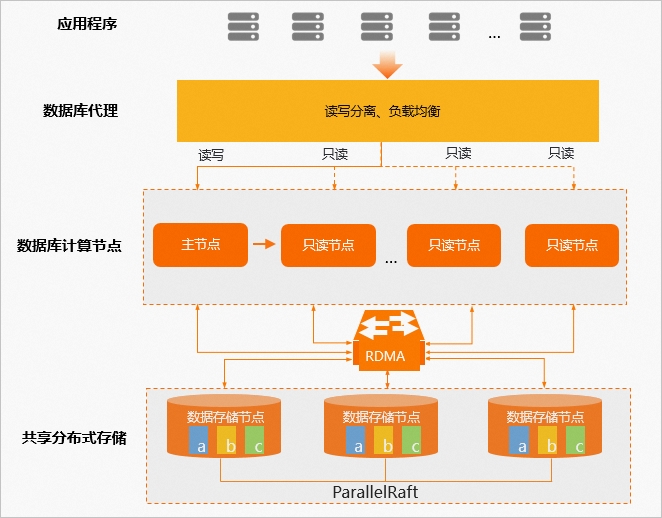
最全Hadoop3.4.2安装指南
1. 安装前准备
准备3台服务器,我是用3台虚拟机做实验:
192.168.110.11 k8s-master
192.168.110.12 k8s-node-1
192.168.110.13 k8s-node-1
这是我以前安装k8s时搭建的机组,每台4C4GB,直接沿用;
按装好JDK1.8,并设置好环境变量;
export JAVA_HOME=/usr/local/jdk1.8.0_471
export PATH=$JAVA_HOME/bin:$PATH
注:为什么使用jdk1.8?因为跑Hive3.1.3只能使用jdk1.8
修改每台服务器的hosts文件:vim /etc/hosts
192.168.110.11 k8s-master
192.168.110.12 k8s-node-1
192.168.110.13 k8s-node-2
设置从k8s-master到k8s-node-1、k8s-node-2的免密登录:
进入.ssh目录,依次执行以下命令
$ cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
$ rm ./id_rsa* # 删除之前生成的公匙(如果有)
$ ssh-keygen -t rsa # 一直按回车就可以
cat ./id_rsa.pub >> ./authorized_keys
这样,执行命令:ssh k8s-master 就不用输入密码,执行exit退出,将 authorized_keys 文件复制到k8s-node-1、k8s-node-2的~/.ssh目录,验证免密登录:ssh k8s-node-1
将hadop安装包放到目录:/cloud/,解压并重命名文件夹为hadoop3.4.2
设置hadoop环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_471
export HADOOP_HOME=/cloud/hadoop-3.4.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
执行命令:source /etc/profile
2. 修改配置文件
进入目录:/cloud/hadoop-3.4.2/etc/hadoop
修改core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://k8s-master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/cloud/hadoop-3.4.2/tmp</value>
</property>
<!-- 静态用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 启用WebHDFS -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:9864</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>k8s-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>k8s-master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/cloud/hadoop-3.4.2</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/cloud/hadoop-3.4.2</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/cloud/hadoop-3.4.2</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- 关键:绑定到所有接口 -->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- RPC地址也使用localhost -->
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8031</value>
</property>
<!-- NodeManager配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- Web代理 -->
<property>
<name>yarn.web-proxy.address</name>
<value>localhost:8089</value>
</property>
</configuration>
修改文件workers
k8s-node-1
k8s-node-2
3. 启动hadoop
3.1 格式化hadoop
进入目录:/cloud/hadoop-3.4.2/etc/hadoop,执行一下命令
hdfs namenode -format -force
3.2 启动hdfs和yarn
# 先启动HDFS
sbin/start-dfs.sh
# 再启动YARN
sbin/start-yarn.sh
为了方便运维,使用启动脚本操作:start-hadoop.sh
#!/bin/bash
#hadoop用户环境变量
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
# 启动HDFS
echo "Starting HDFS..."
sbin/start-dfs.sh
# 启动YARN(如果需要)
echo "Starting YARN..."
sbin/start-yarn.sh
# 启动History Server(如果需要)
echo "Starting History Server..."
sbin/mr-jobhistory-daemon.sh start historyserver
重启脚本:restart-all.sh
#!/bin/bash
echo "=== Hadoop集群重启脚本 ==="
echo "开始时间: $(date)"
echo ""
# 1. 停止服务
echo "1. 停止服务..."
echo "停止历史服务器..."
sbin/mr-jobhistory-daemon.sh stop historyserver 2>/dev/null
echo "停止YARN..."
sbin/stop-yarn.sh 2>/dev/null
echo "停止HDFS..."
sbin/stop-dfs.sh 2>/dev/null
# 等待服务停止
sleep 5
# 检查是否停止
echo "检查停止状态..."
jps_result=$(jps | grep -v Jps)
if [ -n "$jps_result" ]; then
echo "警告:以下进程仍在运行:"
echo "$jps_result"
echo "尝试强制停止..."
for pid in $(jps | grep -v Jps | awk '{print $1}'); do
kill -9 $pid 2>/dev/null
done
sleep 3
fi
echo ""
# 2. 设置环境变量
echo "2. 设置环境变量..."
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
echo "环境变量设置完成"
echo ""
# 3. 启动服务
echo "3. 启动服务..."
echo "启动HDFS..."
sbin/start-dfs.sh
# 等待HDFS启动
echo "等待HDFS启动..."
sleep 8
echo "启动YARN..."
sbin/start-yarn.sh
# 等待YARN启动
echo "等待YARN启动..."
sleep 5
echo "启动历史服务器..."
sbin/mr-jobhistory-daemon.sh start historyserver
echo ""
# 4. 检查启动状态
echo "4. 检查集群状态..."
sleep 3
echo "Java进程状态:"
jps
echo ""
echo "HDFS状态:"
hdfs dfsadmin -report 2>/dev/null | grep -E "Live datanodes|Configured Capacity" || echo " 无法获取HDFS状态"
echo ""
echo "YARN状态:"
yarn node -list 2>/dev/null | head -5 || echo " 无法获取YARN状态"
echo ""
echo "Web UI地址:"
echo " NameNode: http://$(hostname):9870"
echo " ResourceManager: http://$(hostname):8088"
echo ""
echo "结束时间: $(date)"
echo "=== 重启完成 ==="
3.3 验证是否成功
执行jps看到
4. 浏览器查看Web界面
4.1 Hadoop 2.x vs 3.x 端口对比
| 服务 | Hadoop 2.x 端口 | Hadoop 3.x 端口 | 说明 |
|---|---|---|---|
| NameNode HTTP | 50070 | 9870 | Web管理界面 |
| NameNode HTTPS | 50470 | 9871 | 加密Web界面 |
| NameNode RPC | 8020/9000 | 8020/9000 | 客户端RPC通信 |
| DataNode HTTP | 50075 | 9864 | DataNode Web界面 |
| DataNode HTTPS | 50475 | 9865 | DataNode加密Web |
| DataNode IPC | 50020 | 9867 | DataNode IPC |
| DataNode RPC | 50010 | 9866 | DataNode数据传输 |
| SecondaryNameNode HTTP | 50090 | 9868 | SecondaryNameNode Web |
| SecondaryNameNode HTTPS | 50091 | 9869 | SecondaryNameNode加密Web |
4.2 YARN 相关端口
| 端口 | 服务 | 用途 |
|---|---|---|
| 8088 | ResourceManager Web UI | YARN集群管理界面 |
| 8030-8033 | ResourceManager RPC | 应用提交、资源申请 |
| 8040-8042 | NodeManager Web UI | 节点资源管理 |
| 8080 | JobHistory Server | MapReduce作业历史 |
4.3 管理界面
hdfs管理界面:http://localhost:9870 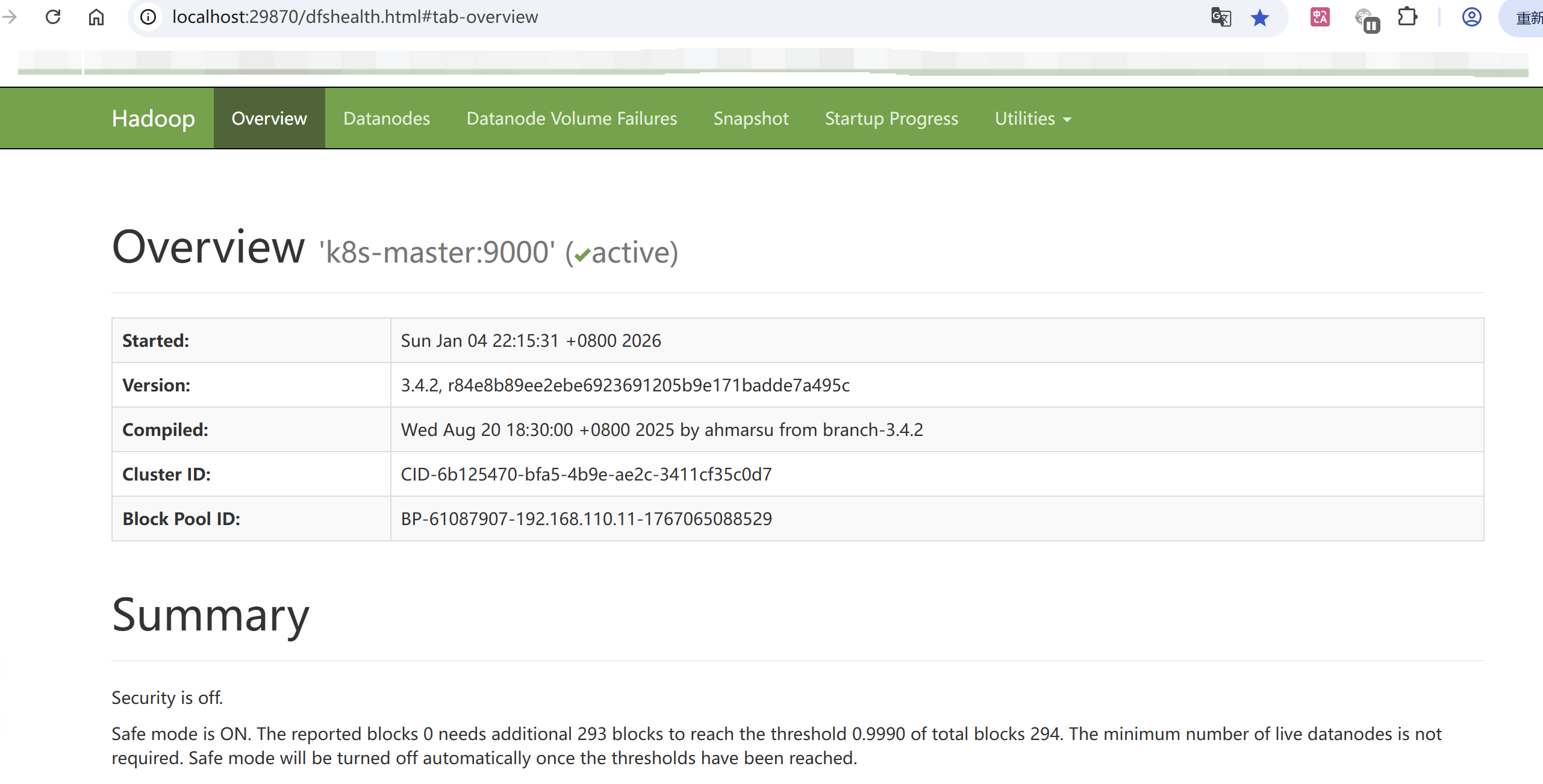
MR的管理界面:http://localhost:8088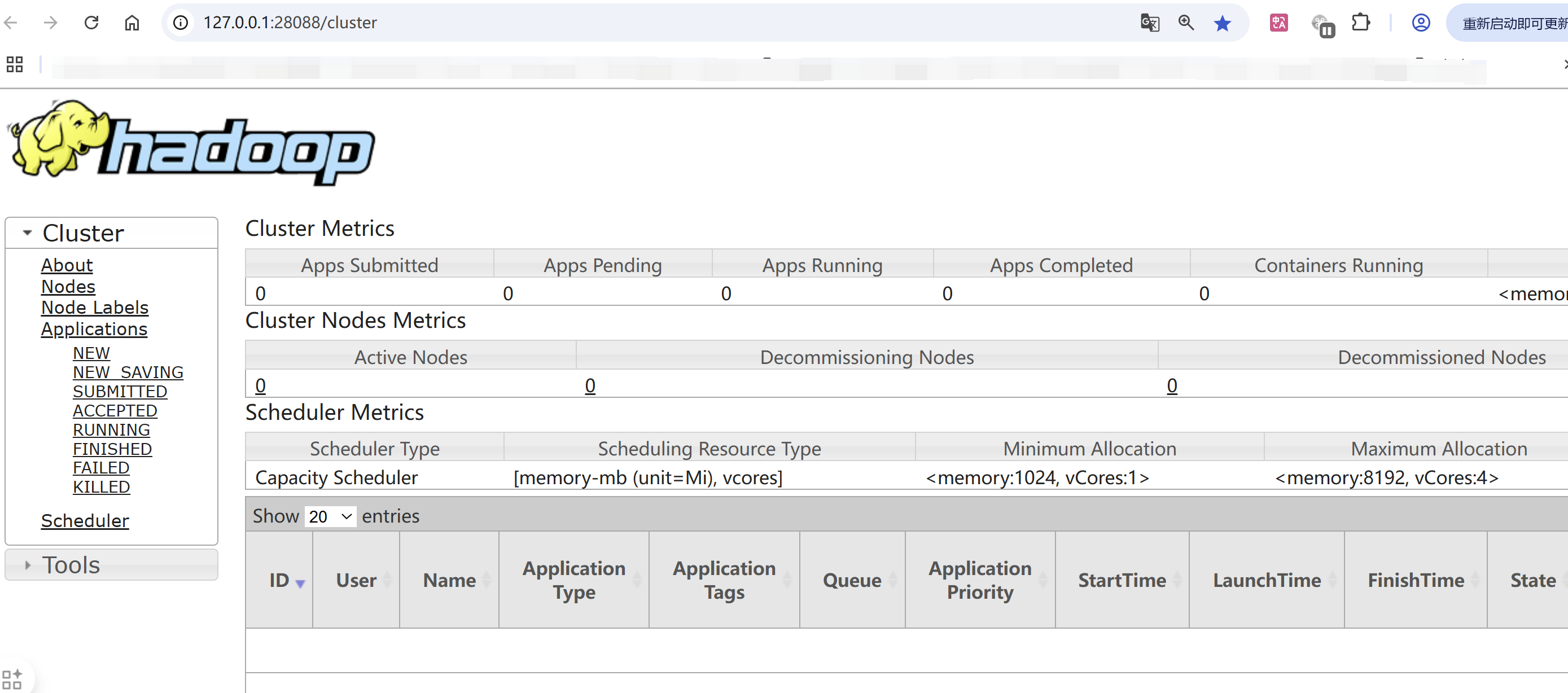
5.按装过程报错处理
[root@k8s-master hadoop-3.4.2]# sbin/start-dfs.sh
Starting namenodes on [locahost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [k8s-master]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
不能使用root用户启动hdfs,改为其他用户即可;切换用户继续。
[root@k8s-master hadoop-3.4.2]# su vagrant
[vagrant@k8s-master hadoop-3.4.2]$ sbin/start-dfs.sh
Starting namenodes on [locahost]
locahost: ssh: Could not resolve hostname locahost: Name or service not known
Starting datanodes
k8s-node-2: Warning: Permanently added 'k8s-node-2' (ECDSA) to the list of known hosts.
k8s-node-2: Permission denied (publickey,password).
k8s-node-1: Warning: Permanently added 'k8s-node-1,192.168.110.12' (ECDSA) to the list of known hosts.
k8s-node-1: Permission denied (publickey,password).
Starting secondary namenodes [k8s-master]
k8s-master: Warning: Permanently added 'k8s-master,192.168.110.11' (ECDSA) to the list of known hosts.
k8s-master: Permission denied (publickey,password).
先设置hadoop用户环境变量,修改etc/hadoop/hadoop-env.sh
# 设置Hadoop用户环境变量
# 找到export HDFS_NAMENODE_USER 把值改为root,并添加一下环境变量
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
改完继续执行启动脚本
[root@k8s-master hadoop-3.4.2]# sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
k8s-node-1: bash: /cloud/hadoop-3.4.2/bin/hdfs: No such file or directory
k8s-node-2: bash: /cloud/hadoop-3.4.2/bin/hdfs: No such file or directory
每个节点都要安装hadoop, 直接同步hadoop安装目录到各节点:
rsync -avz /cloud/hadoop-3.4.2/ root@k8s-node-1:/cloud/hadoop-3.4.2/
rsync -avz /cloud/hadoop-3.4.2/ root@k8s-node-2:/cloud/hadoop-3.4.2/
继续启动,成功标志
[root@k8s-master hadoop-3.4.2]# sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [k8s-master]
[root@k8s-master hadoop-3.4.2]# sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
- 本文标签: 大数据 hadoop
- 本文链接: https://t-leader.cn/article/11
- 版权声明: 本文由站长原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权